Incremental Accumulation of Linguistic Context in Artificial and Biological Neural Networks
Abstract
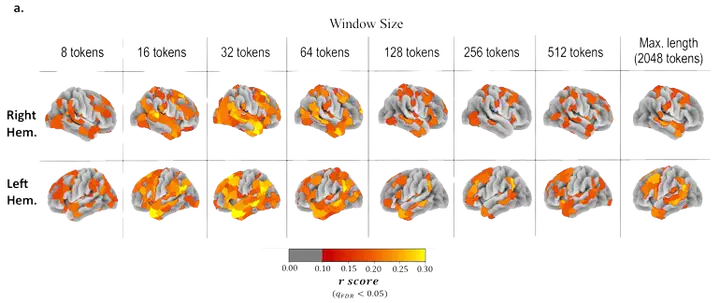
Large Language Models (LLMs) have shown success in predicting neural signals associated with narrative processing, but their approach to integrating context over large timescales differs fundamentally from that of the human brain. In this study, we show how the brain, unlike LLMs that process large text windows in parallel, integrates short-term and long-term contextual information through an incremental mechanism. Using fMRI data from 219 participants listening to spoken narratives, we first demonstrate that LLMs predict brain activity effectively only when using short contextual windows of up to a few dozen words. Next, we introduce an alternative LLM-based incremental-context model that combines incoming short-term context with an aggregated, dynamically updated summary of prior context. This model significantly enhances the prediction of neural activity in higher-order regions involved in long-timescale processing. Our findings reveal how the brain’s hierarchical temporal processing mechanisms enable the flexible integration of information over time, providing valuable insights for both cognitive neuroscience and AI development.
Yoav Meiri
Msc. Student in Data Science
I am an MSc student in Data Science at the Technion, studying human language processing through computational modeling of reading behavior and linguistic patterns using eye-tracking data.